-
超乎想象的 AI、 尽情释放
在华硕的支持下,将您的 NVIDIA GB200 概念化为现实
通过由 NVIDIA GB200 Grace™ Blackwell Superchips 驱动的华硕 AI POD,释放您 AI 基础架构的完整潜力。这个增强型的 AI 系统旨在加速实时万亿参数模型,例如 LLM 和 MoE,为大型 AI 项目、超大规模数据中心和研究计划提供强大的性能。华硕 AI POD 专为推动创新的企业和研发团队量身打造,让您能够突破可能的界限,同时通过华硕独有的软件驱动方法加速上市时间。

-

Blackwell 架构 GPU
采用 TSMC 4NP 制程的 2080 亿个晶体管
-

第二代 Transformer Engine
通过 FP4 启用,性能提升一倍
-

第五代 NVLink & NVLink Switch
1.8 TB/s GPU-GPU 互连
-
-
NVIDIA Blackwell GPU 突破
华硕 AI POD 包含 NVIDIA GB200 Grace™ Blackwell 超级芯片,每个芯片封装 2080 亿个晶体管。NVIDIA Blackwell GPU 具有两个光罩尺寸限制的晶粒,通过每秒 10 TB (TB/s) 的芯片对芯片互连连接在统一的单个 GPU 中。NVIDIA GB200 NVL72 在 FP4 精度下提供 1,440 PFLOPS 的运算能力,利用其先进的 Tensor Cores 和第五代 NVLink 互连来实现 AI 工作负载的高性能。
-
-

 1 1 2 3 4 5 5 6 6 7 8 9 10
1 1 2 3 4 5 5 6 6 7 8 9 101NVIDIA BlueField®-3 DPU (B3240)
2PDB
3内部歧管
4风扇区域
5NVIDIA ConnectX®-7 夹层网卡
6NVIDIA GB200 Grace™ Blackwell 超级芯片
7HMC 模块
8液体散热出口
9总线夹
10液体散热入口
-

 1 2 2 3 4 5 6 7 8 9 9
1 2 2 3 4 5 6 7 8 9 91NVIDIA BlueField®-3 DPU (B3240)
22 x OSFP 400G
31G PXE
48* E1.S
5BMC
6USB 3.2
7miniDP
8NVIDIA BlueField®-3 DPU (B3240)
92 x OSFP 400G
-

 1 2 2 3 4 4 5
1 2 2 3 4 4 51液体散热出口
2NVIDIA® NVLink™ 接头
3总线夹
4NVIDIA® NVLink™ 接头
5液体散热入口
-
-

-
30XLLM 推理NVIDIA H100 Tensor Core GPU
-
4XLLM 训练H100
-
25X能源效率H100
-
18X数据处理CPU
- LLM 推理和能源效率:TTL = 50 毫秒 (ms) 实时,FTL = 5 秒,32,768 输入/1,024 输出, NVIDIA HGX™ H100 通过 InfiniBand (IB) 扩展与 GB200 NVL72 比较,训练 1.8T MOE 4096x HGX H100 扩展 通过 IB 与 456x GB200 NVL72 通过 IB 扩展比较。丛集大小:32,768
- 具有 Snappy / Deflate 压缩的数据库联接和聚合工作负载,源自 TPC-H Q4 查询。 x86、H100 单个 GPU 和来自 GB200 NLV72 的单个 GPU 与 Intel Xeon 的自定义查询实现 8480+
- 预计性能如有变更,恕不另行通知
-
-
大规模的 AI 基础架构
华硕通过利用强大的 NVIDIA GB200 NVL72,持续展示其在建构 AI 基础架构方面的专业知识。 这个先进的系统安装在具有多个运算节点的单个机架中,消耗约 120kW 的电力。 鉴于这种巨大的电力需求,数据中心营运商必须重新评估和升级现有的拓扑和配置。优化工作应侧重于通过增强的散热、稳定的网络连接以及设施的整体架构完整性来确保性能稳定。随着 AI 工作负载变得越来越严苛,这些基础架构的改进对于在保持运作稳定性的同时,实现性能和效率目标至关重要。
-
优化效率,降低热量
液冷架构
华硕与合作伙伴合作,提供全面的机柜级液冷解决方案。这些解决方案包括 CPU/GPU 冷板、散热分配单元和散热塔,所有这些都旨在更大限度地减少功耗并优化数据中心的电源使用效率 (PUE)。
-

液体到风冷解决方案
非常适合具有紧凑型设施的小型数据中心。
旨在满足现有风冷数据中心的需求,并轻松与当前基础架构整合。
非常适合寻求立即实施和部署的企业。 -

液体到液体解决方案
非常适合具有高工作负载的大规模、广泛的基础架构。
提供长期的低 PUE,并随着时间的推移保持能源效率。
降低 TCO 以实现更大价值和具有成本效益的营运。
-
-
超快
NVIDIA GB200 NVL72 中的第五代 NVLink 技术
NVIDIA NVLink Switch 具有 144 个接口,交换容量为 14.4 TB/s,允许九个交换器与单个 NVLink 网域内 72 个 NVIDIA Blackwell GPU 中的每一个上的 NVLink 接口互连。
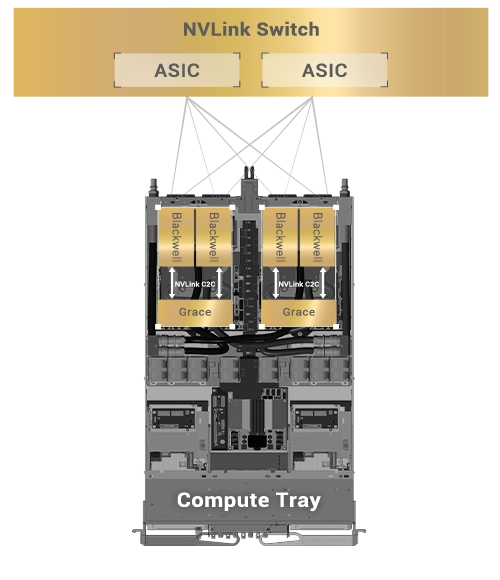
单个运算托盘中的 NVLink 连接,确保直接连接到所有 GPU
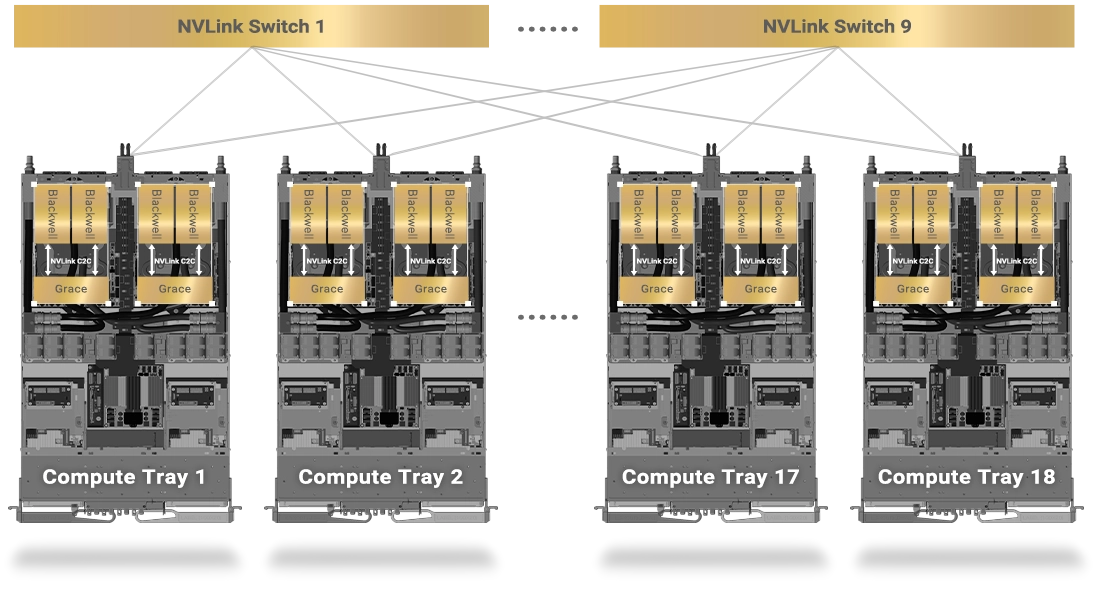
单个机架中的 NVLink 连接
-
华硕 Premiere Service Suite
通过从硬件到应用程序的全方位整合来改造数据中心
华硕通过提供从设计和建构到实施、验证、测试和部署的全方位服务,重新定义了其基础架构服务架构。这与云端应用程序服务无缝整合,所有这些都通过客制化的、客户特定的服务模型交付,以满足不同的客户 需求。
-

架构设计
-

大规模部署
-

配置测试
-

客制化
-

云端服务
-

项目交付

-
-
加速您的上市 时间
华硕自有的软件和控制器
NVIDIA NVLink Switch 具有 144 个接口,交换容量为 14.4 TB/s,允许九个交换器与单个 NVLink 网域内 72 个 NVIDIA Blackwell GPU 中的每一个上的 NVLink 接口互连。
-
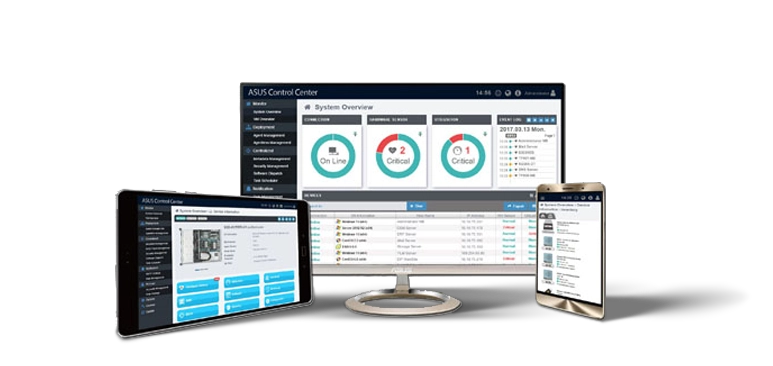
华硕控制中心 (ACC)
集中式 IT 管理软件,用于监控和控制华硕服务器
- Power Master – 针对数据中心的有性能源控制
- 轻松搜索和控制您的装置
- 轻松快速地增强信息安全
-
华硕基础架构部署中心 (AIDC)
单一管理控制台,可实现集中式远程部署
- 自动化和系统化
- 集中式配置控制和管理
- 加速机架级基础架构的部署
-
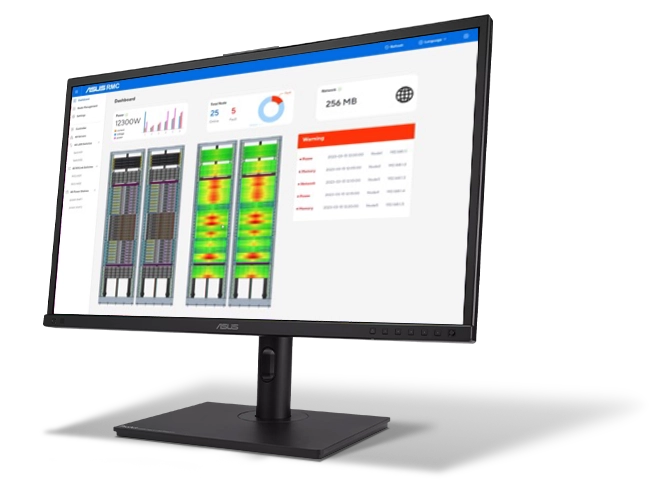
机架管理控制器 (RMC)
用于服务器机架内远程硬件管理的集中式控制器
- 故障排除、管理和维护
- 批次监控
-


